3 Docker
cmd
$ docker build -t helloworld .
$ docker run -p 4000:80 helloworld
$ curl http://localhost:4000
$ docker tag helloworld jianchengwang/helloworld:v1
$ docker push jianchengwang/helloworld:v1
docker exec
Linux Namespace 创建的隔离空间虽然看不见摸不着,但一个进程的 Namespace 信息在宿主机上是确确实实存在的,并且是以一个文件的方式存在
$ docker inspect --format '{{ .State.Pid }}' 4ddf4638572d
25686
$ ls -l /proc/25686/ns
total 0
lrwxrwxrwx 1 root root 0 Aug 13 14:05 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 ipc -> ipc:[4026532278]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 mnt -> mnt:[4026532276]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 net -> net:[4026532281]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 pid -> pid:[4026532279]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 pid_for_children -> pid:[4026532279]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 uts -> uts:[4026532277]
可以看到,一个进程的每种 Linux Namespace,都在它对应的 /proc/进程号/ns 下有一个对应的虚拟文件,并且链接到一个真实的 Namespace 文件上。
这也就意味着:一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到"进入"这个进程所在容器的目的,这正是 docker exec 的实现原理。而这个操作所依赖的,乃是一个名叫 setns() 的 Linux 系统调用
$ docker run -it --net container:4ddf4638572d busybox ifconfig
$ docker run -it --net host busybox ifconfig
指定–net=host,就意味着这个容器不会为进程启用 Network Namespace。这就意味着,这个容器拆除了 Network Namespace 的“隔离墙”,所以,它会和宿主机上的其他普通进程一样,直接共享宿主机的网络栈。
docker commit
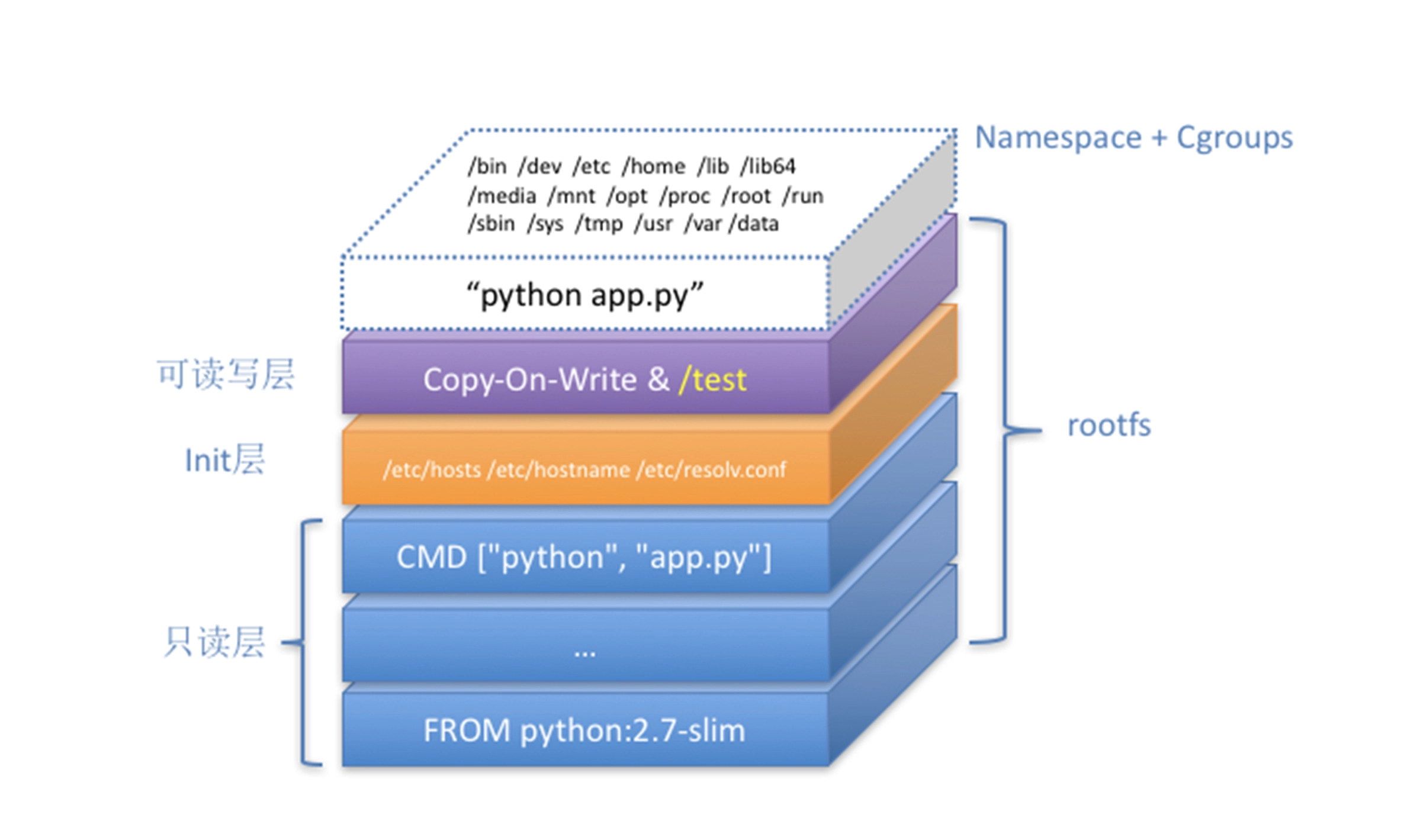
docker commit,实际上就是在容器运行起来后,把最上层的“可读写层”,加上原先容器镜像的只读层,打包组成了一个新的镜像
而由于使用了联合文件系统,你在容器里对镜像 rootfs 所做的任何修改,都会被操作系统先复制到这个可读写层,然后再修改。这就是所谓的:Copy-on-Write。
而正如前所说,Init 层的存在,就是为了避免你执行 docker commit 时,把 Docker 自己对 /etc/hosts 等文件做的修改,也一起提交掉。
volume
Volume 机制,允许你将宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改操作。
$ docker run -v /test ...
$ docker run -v /home:/test ...
当容器进程被创建之后,尽管开启了 Mount Namespace,但是在它执行 chroot(或者 pivot_root)之前,容器进程一直可以看到宿主机上的整个文件系统。
而宿主机上的文件系统,也自然包括了我们要使用的容器镜像。这个镜像的各个层,保存在 /var/lib/docker/aufs/diff 目录下,在容器进程启动后,它们会被联合挂载在 /var/lib/docker/aufs/mnt/ 目录中,这样容器所需的 rootfs 就准备好了。
更重要的是,由于执行这个挂载操作时,“容器进程”已经创建了,也就意味着此时 Mount Namespace 已经开启了。所以,这个挂载事件只在这个容器里可见。你在宿主机上,是看不见容器内部的这个挂载点的。这就保证了容器的隔离性不会被 Volume 打破。
而这里要使用到的挂载技术,就是 Linux 的绑定挂载(bind mount)机制。它的主要作用就是,允许你将一个目录或者文件,而不是整个设备,挂载到一个指定的目录上。并且,这时你在该挂载点上进行的任何操作,只是发生在被挂载的目录或者文件上,而原挂载点的内容则会被隐藏起来且不受影响。
容器 Volume 里的信息,并不会被 docker commit 提交掉;但这个挂载点目录 /test 本身,则会出现在新的镜像当中。
network
在 Linux 中,能够起到虚拟交换机作用的网络设备,是网桥(Bridge)。它是一个工作在数据链路层(Data Link)的设备,主要功能是根据 MAC 地址学习来将数据包转发到网桥的不同端口(Port)上。参考
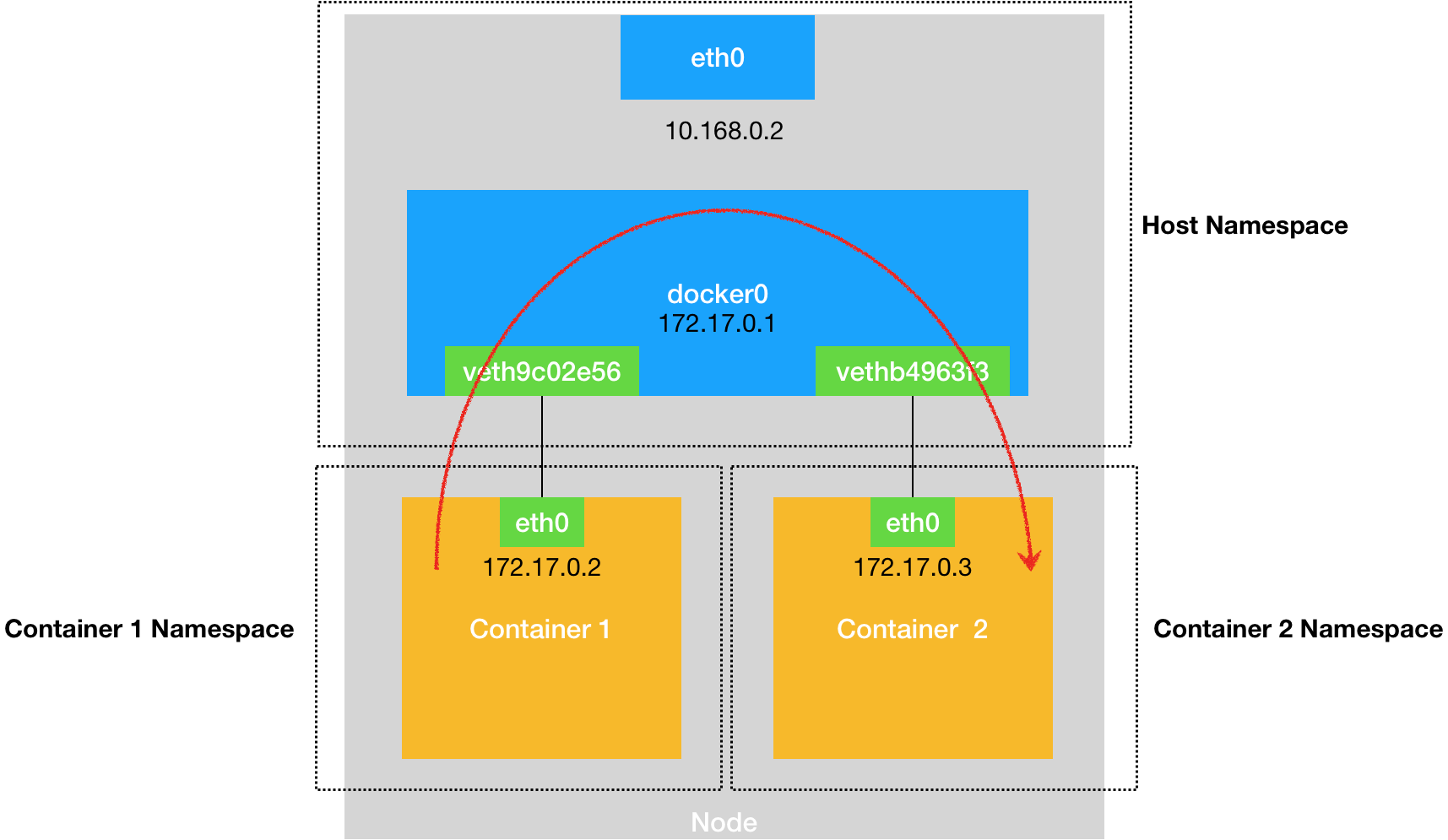
而为了实现上述目的,Docker 项目会默认在宿主机上创建一个名叫 docker0 的网桥,凡是连接在 docker0 网桥上的容器,就可以通过它来进行通信。
Veth Pair 设备的特点是:它被创建出来后,总是以两张虚拟网卡(Veth Peer)的形式成对出现的。并且,从其中一个“网卡”发出的数据包,可以直接出现在与它对应的另一张“网卡”上,哪怕这两个“网卡”在不同的 Network Namespace 里。这就使得 Veth Pair 常常被用作连接不同 Network Namespace 的“网线”。
$ dokcer run -d --name nginx-1 nginx
# 在宿主机上
$ docker exec -it nginx-1 /bin/bash
# 在容器里
root@2b3c181aecf1:/# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.2 netmask 255.255.0.0 broadcast 0.0.0.0
inet6 fe80::42:acff:fe11:2 prefixlen 64 scopeid 0x20<link>
ether 02:42:ac:11:00:02 txqueuelen 0 (Ethernet)
RX packets 364 bytes 8137175 (7.7 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 281 bytes 21161 (20.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
可以看到,这个容器里有一张叫作 eth0 的网卡,它正是一个 Veth Pair 设备在容器里的这一端。
通过 route 命令查看 nginx-1 容器的路由表,我们可以看到,这个 eth0 网卡是这个容器里的默认路由设备;所有对 172.17.0.0/16 网段的请求,也会被交给 eth0 来处理(第二条 172.17.0.0 路由规则)。而这个 Veth Pair 设备的另一端,则在宿主机上。你可以通过查看宿主机的网络设备看到它,如下所示:
# 在宿主机上
$ ifconfig
...
docker0 Link encap:Ethernet HWaddr 02:42:d8:e4:df:c1
inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:d8ff:fee4:dfc1/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:309 errors:0 dropped:0 overruns:0 frame:0
TX packets:372 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:18944 (18.9 KB) TX bytes:8137789 (8.1 MB)
veth9c02e56 Link encap:Ethernet HWaddr 52:81:0b:24:3d:da
inet6 addr: fe80::5081:bff:fe24:3dda/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:288 errors:0 dropped:0 overruns:0 frame:0
TX packets:371 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:21608 (21.6 KB) TX bytes:8137719 (8.1 MB)
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242d8e4dfc1 no veth9c02e56
通过 ifconfig 命令的输出,你可以看到,nginx-1 容器对应的 Veth Pair 设备,在宿主机上是一张虚拟网卡。它的名字叫作 veth9c02e56。并且,通过 brctl show 的输出,你可以看到这张网卡被“插”在了 docker0 上。
可以通过打开 iptables 的 TRACE 功能查看到数据包的传输过程,具体方法如下所示
# 在宿主机上执行
$ iptables -t raw -A OUTPUT -p icmp -j TRACE
$ iptables -t raw -A PREROUTING -p icmp -j TRACE
通过上述设置,你就可以在 /var/log/syslog 里看到数据包传输的日志了
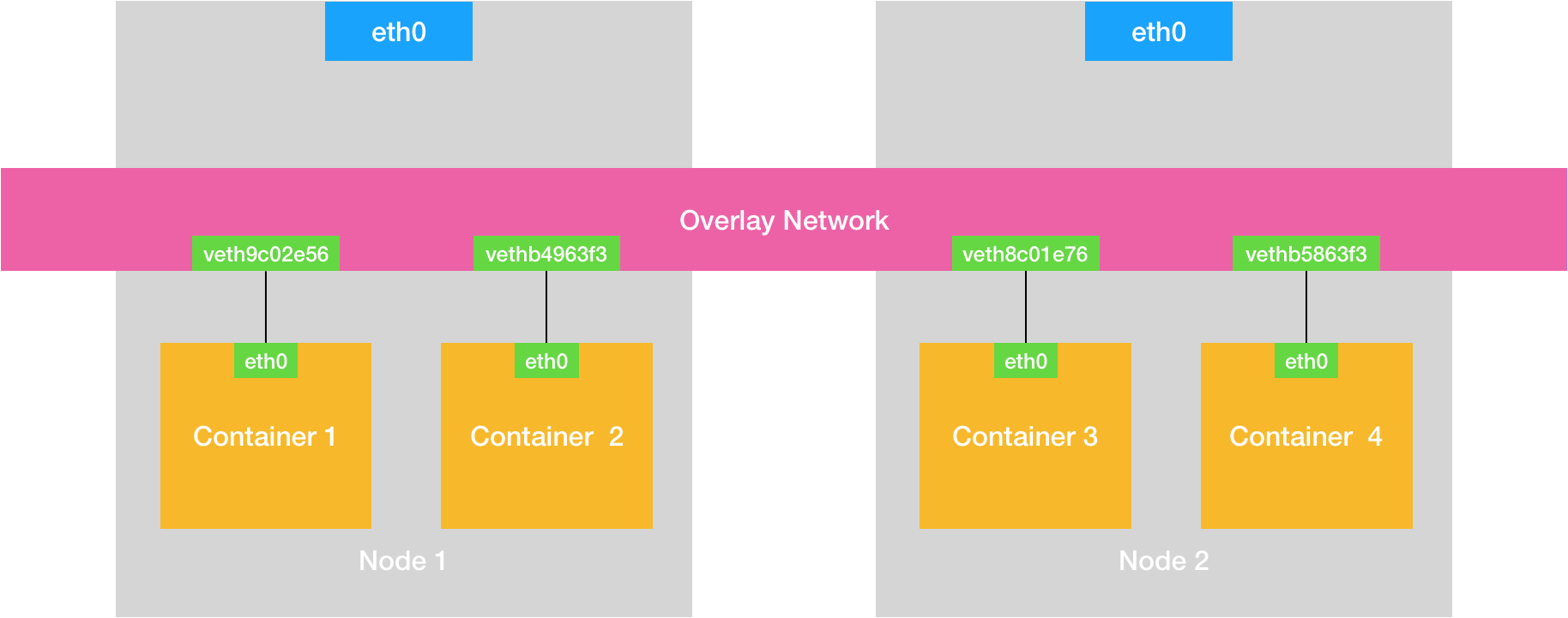
在 Docker 的默认配置下,一台宿主机上的 docker0 网桥,和其他宿主机上的 docker0 网桥,没有任何关联,它们互相之间也没办法连通。所以,连接在这些网桥上的容器,自然也没办法进行通信了。
不过,万变不离其宗。如果我们通过软件的方式,创建一个整个集群“公用”的网桥,然后把集群里的所有容器都连接到这个网桥上,不就可以相互通信了吗?
multistage-build
多阶段构建的本质其实就是将镜像构建过程拆分成编译过程和运行过程。第一个阶段对应编译的过程,负责生成可执行文件;第二个阶段对应运行过程,也就是拷贝第一阶段的二进制可执行文件,并为程序提供运行环境。
# syntax=docker/dockerfile:1
# Step 1: build golang binary
FROM golang:1.17 as builder
WORKDIR /opt/app
COPY . .
RUN go build -o example
# Step 2: copy binary from step1
FROM ubuntu:latest
WORKDIR /opt/app
COPY --from=builder /opt/app/example ./example
CMD ["/opt/app/example"]
cache
尽量使用 Docker 构建缓存。要使用 Golang 依赖的缓存,最简单的办法是:先复制依赖文件,再下载依赖,最后再复制源码进行编译。
# Step 1: build golang binary
FROM golang:1.17 as builder
WORKDIR /opt/app
COPY go.* ./
RUN go mod download
COPY . .
RUN go build -o example