K8s Network
CNI 的设计思想,就是:Kubernetes 在启动 Infra 容器之后,就可以直接调用 CNI 网络插件,为这个 Infra 容器的 Network Namespace,配置符合预期的网络栈。
关于网络的架构,这里不多叙说,可自行了解。
Service
$ kubectl expose deploy ngx-dep --port=80 --target-port=80 --dry-run=client -o yaml
kubectl apply -f hostnames-nodeport.yaml -n example
kubectl get endpoints hostnames -n example
kubectl get svc -n example
Service 是由 kube-proxy 组件,加上 iptables 来共同实现的。举个例子,对于我们前面创建的名叫 hostnames 的 Service 来说,一旦它被提交给 Kubernetes,那么 kube-proxy 就可以通过 Service 的 Informer 感知到这样一个 Service 对象的添加。而作为对这个事件的响应,它就会在宿主机上创建这样一条 iptables 规则
(你可以通过 iptables-save 看到它),如下所示:
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3
可以看到,这条 iptables 规则的含义是:凡是目的地址是 10.0.1.175、目的端口是 80 的 IP 包,都应该跳转到另外一条名叫 KUBE-SVC-NWV5X2332I4OT4T3 的 iptables 链进行处理。
而我们前面已经看到,10.0.1.175 正是这个 Service 的 VIP。所以这一条规则,就为这个 Service 设置了一个固定的入口地址。并且,由于 10.0.1.175 只是一条 iptables 规则上的配置,并没有真正的网络设备,所以你 ping 这个地址,是不会有任何响应的。
那么,我们即将跳转到的 KUBE-SVC-NWV5X2332I4OT4T3 规则,又有什么作用呢?实际上,它是一组规则的集合,如下所示:
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-X3P2623AGDH6CDF3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -j KUBE-SEP-57KPRZ3JQVENLNBR
可以看到,这一组规则,实际上是一组随机模式(–mode random)的 iptables 链。而随机转发的目的地,分别是 KUBE-SEP-WNBA2IHDGP2BOBGZ、KUBE-SEP-X3P2623AGDH6CDF3 和 KUBE-SEP-57KPRZ3JQVENLNBR。而这三条链指向的最终目的地,其实就是这个 Service 代理的三个 Pod。所以这一组规则,就是 Service 实现负载均衡的位置。
一直以来,基于 iptables 的 Service 实现,都是制约 Kubernetes 项目承载更多量级的 Pod 的主要障碍。而 IPVS 模式的 Service,就是解决这个问题的一个行之有效的方法。
在大规模集群里,非常建议为 kube-proxy 设置–proxy-mode=ipvs 来开启这个功能。它为 Kubernetes 集群规模带来的提升,还是非常巨大的。
Service 对象的域名完全形式是[serviceName].[namespace].svc.cluster.local,同一个命名空间互通可以直接用[serviceName]
ClusterIP
参考minimal-ingress.yaml
ClusterIP 公开集群内部IP上的服务。选择此值将使服务只能从集群内访问。如果您没有显式地为服务指定类型,则使用默认值。您可以使用Ingress或Gateway API向公众公开服务。
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.3.1/deploy/static/provider/cloud/deploy.yaml
在多数实际项目中,Ingress 都是服务暴露的最佳实践。
NodePort
参考hostnames-nodeport.yaml
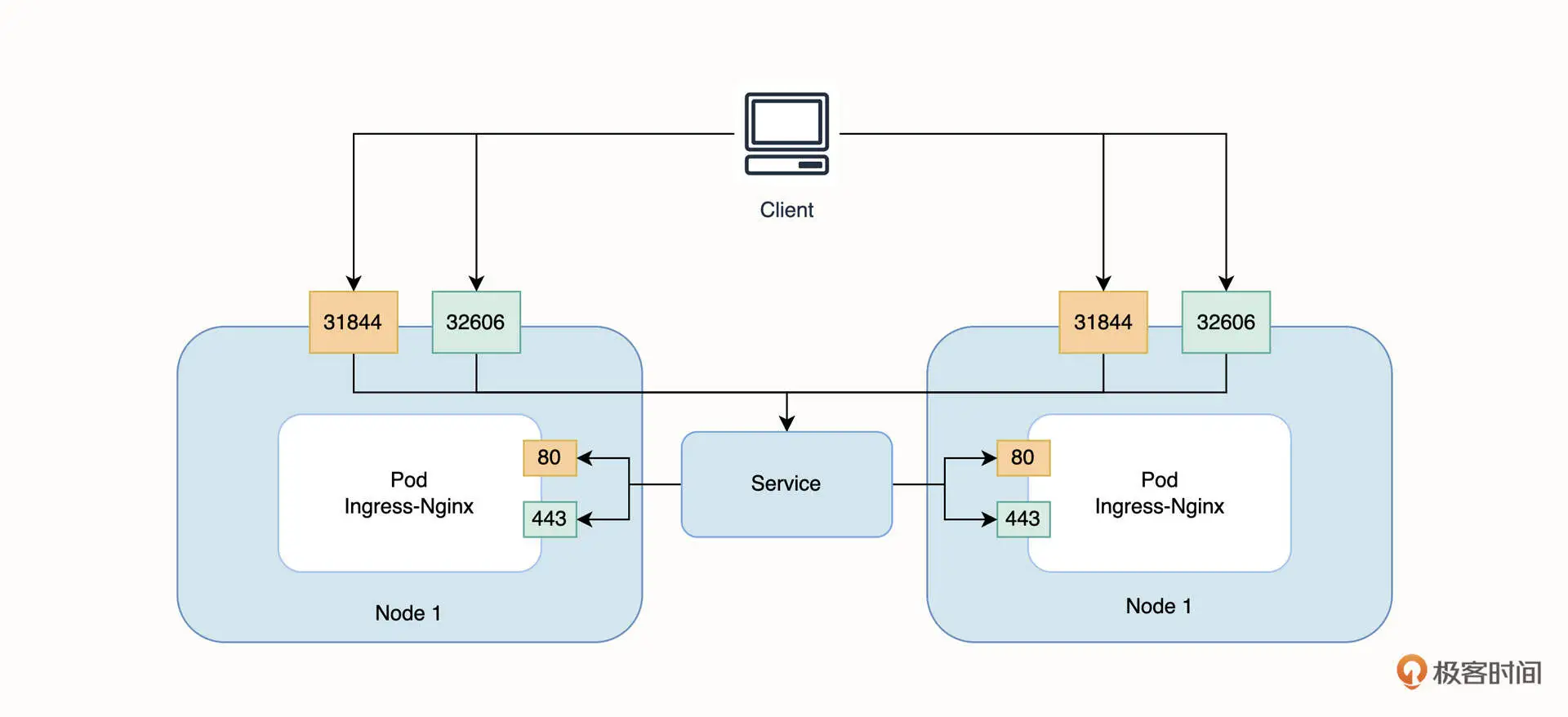
NodePort 的暴露方式虽然可以直接复用 Kubernetes 节点的公网 IP,但并不推荐在生产环境使用它。主要的原因有两个。
首先,直接对外暴露服务不利于统一管理外部请求流量。
其次,一个端口只能绑定一个服务,并且默认的端口范围是有限的,所以在较大规模场景时使用容易产生端口冲突。如果你希望临时访问集群内的业务服务,建议你使用端口转发进行访问,它适用于大多数的临时场景。
LoadBalance
参考myservice-loadbalance.yaml
使用云提供商的负载平衡器在外部公开服务。
Loadbalancer 类型一般依赖于云厂商实现。当 Service 被声明为负载均衡器类型时,云厂商会创建一个负载均衡器实例并和集群的 Service 关联,借助负载均衡器的外网 IP 地址,实现 Service 的对外暴露。此时,相当于每一个 Loadbalancer 类型的 Service 都具有一个外网 IP 地址,所有流量先通过负载均衡器,再转发到对应的 Service 当中,如下图所示。
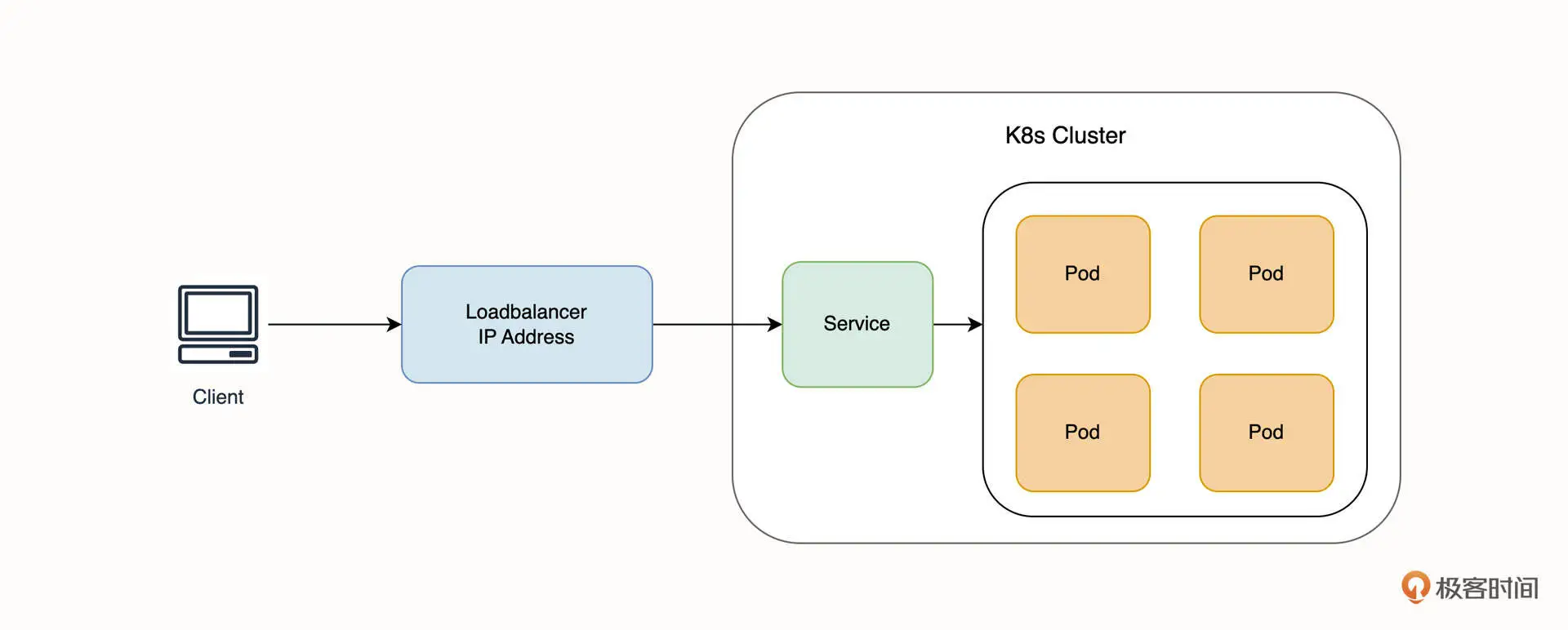
Loadbalancer 类型相比较 NodePort 有一定的优势。比如,理论上来说它暴露服务的数量不会受到端口数量的限制。从架构设计上来说,暴露服务和 Kubernetes 节点实现了解耦,是一个非常不错的选型。需要注意的是,每声明一个 Loadbalancer 类型的 Service,都会创建一个新的负载均衡器实例,负载均衡器由于具有固定 IP 地址,所以费用也相对较高,并且还需要为流量额外付费。
本地集群部署LoadBalance请参考 metallb
ExternalName
参考myservice-externalname.yaml
Headless Service
参考mysqlsvc-headless.yaml
有时您不需要负载均衡和单个服务IP。在这种情况下,您可以通过显式地为集群IP (.spec. clusterip)指定“None”来创建所谓的“无头”服务。
最常见的是抽象化对 Kubernetes Pod 的访问,但是它们也可以抽象化其他种类的后端,比如外部的数据库集群等。
Ingress
参考 官方文档,不多赘述