K8s Workload
Pods
Pod是k8s最小的编排单位,类似进程组的概念。Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume。
基于容器设计模式,感兴趣的可以参考 小论文
$ kubectl run ngx --image=nginx:alpine --dry-run=client -o yaml
apiVersion: v1
kind: Pod
metadata:
name: busy-pod
labels:
owner: chrono
env: demo
region: north
tier: back
spec:
containers:
- image: busybox:latest
name: busy
imagePullPolicy: IfNotPresent
env:
- name: os
value: "ubuntu"
- name: debug
value: "on"
command:
- /bin/echo
args:
- "$(os), $(debug)"
$ kubectl logs busy-pod
$ kubectl get pods
$ kubectl describe pod busy-pod
$ echo 'aaa' > a.txt
$ kubectl cp a.txt ngx-pod:/tmp
$ kubectl exec -it ngx-pod -- sh
workload resources
Deployments
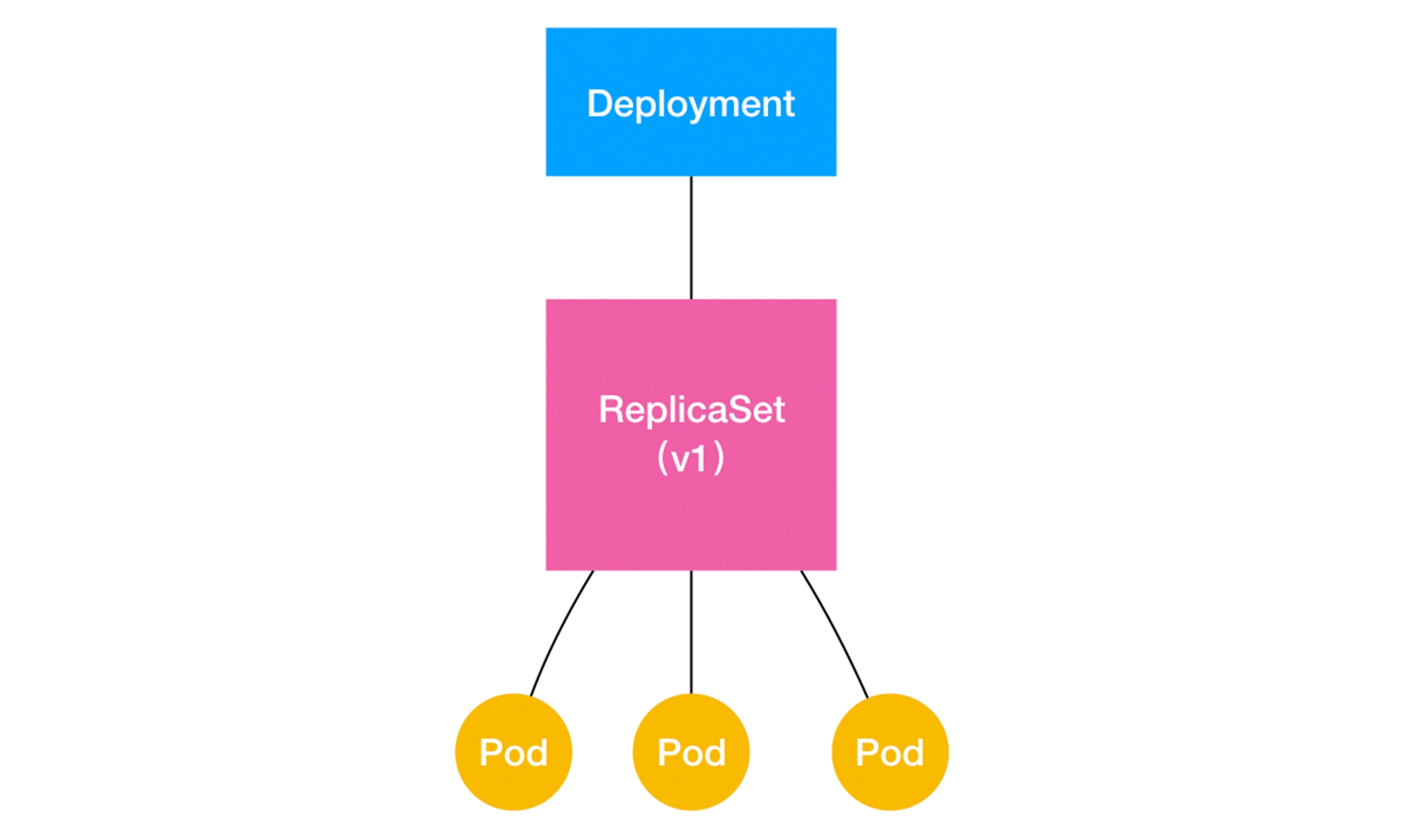
$ kubectl create deployment ngx-dep --image=nginx:alpine --dry-run=client -o yaml
$ kubectl scale --replicas=5 deployment ngx-dep
$ kubectl get pod -l app=nginx
$ kubectl get pod -l 'app in (ngx, nginx, ngx-dep)'
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
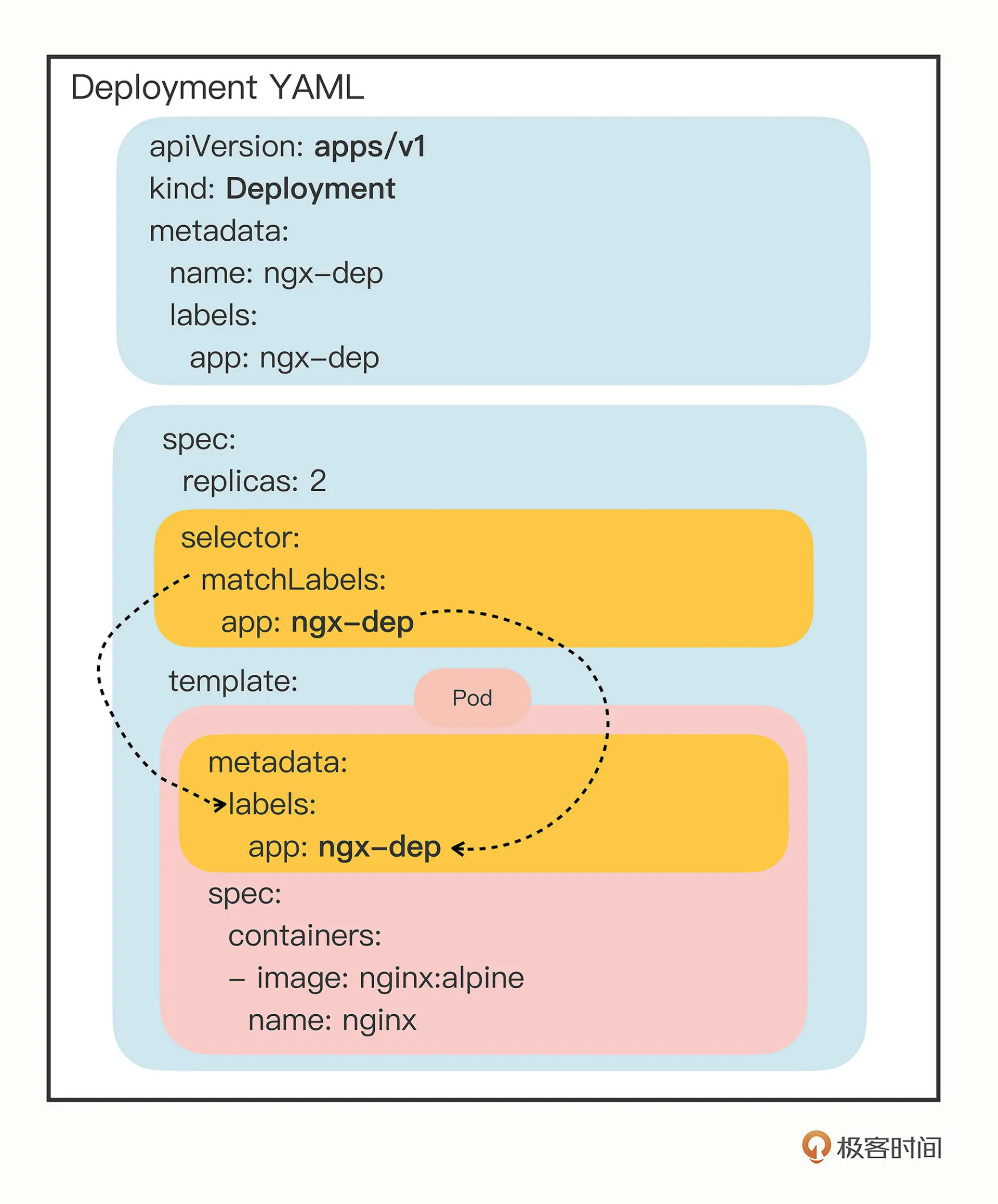
- selector matchLabels 通常跟PodTemplate的metadata.lables一致
- replicas 副本数量
- StrategyType:
Recreate:此策略类型将在创建新 Pod 之前先销毁现有 Pod;RollingUpdate: 滚动更新的方式对 Pod 进行逐个更新,它是默认的更新策略,不会造成业务停机; RollingUpdateStrategy 是对滚动更新更加精细的控制:maxSurge用来指定最大超出期望 Pod 的个数;maxUnavailable是允许 Pod 不可用的数量
Job/CronJob
Job创建一个或多个pod,并将继续重试执行这些pod,直到指定数量的pod成功终止。当pod成功完成时,Job跟踪成功完成的过程。当达到指定的成功完成次数时,任务(即作业)就完成了。
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
backoffLimit: 4
activeDeadlineSeconds: 200
completions: 1
parallelism: 1
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit代表 Job 运行失败之后重新运行的次数,默认值为 6。需要注意的是,Job 的重启时间是呈指数级增长的,例如,下一次 Job 重新运行的时间可能是 10s、20s、40s,最大时间为 6 分钟。completions字段表示 Job 的完成条件,默认值为 1,意味着当有一个 Pod 的状态为“完成”时,Job 也就完成了。parallelism字段表示并行,意思是同时启动几个 Pod 运行任务,默认值为 1 ,意味着默认只启动一个 Pod 运行任务。restartPolicy代表重启策略,如果我们把 restartPolicy 设置为 Never,意味着 Pod 运行失败后将不会被重新启动。除了 Never,我们还可以设置 OnFailure,意思是如果容器进程退出状态码非 0 ,那么 Pod 将会被自动重启,重新执行任务,而在 Deployment 中,restartPolicy 字段只能被设置为 Always。- 当 Job 运行完成后,Pod 的状态将从 Running 转变为 Completed。但我们还可能遇到一种特殊情况,如果任务卡住或者长时间没反应怎么办呢?其实这时候我们可以使用
activeDeadlineSeconds字段控制 Pod 的最长运行时间。在上面的配置中,如果运行时间超过 200 秒,那么 Pod 会被强制终止,并且在事件中显示的终止原因是 DeadlineExceeded。
还有一种和 Job 类似的工作负载类型是 CronJob,它们的区别在于 CronJob 可以设置和 Linux Crontab 一致的表达式,并在特定的时间自动重复运行,例如每分钟自动运行一次。
apiVersion: batch/v1
kind: CronJob
metadata:
name: run-every-minute
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: cronjob
image: busybox:latest
command:
- /bin/sh
- -c
- echo Hello World
Schedule syntax The .spec.schedule field is required. The value of that field follows the Cron syntax:
# ┌───────────── minute (0 - 59)
# │ ┌───────────── hour (0 - 23)
# │ │ ┌───────────── day of the month (1 - 31)
# │ │ │ ┌───────────── month (1 - 12)
# │ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday;
# │ │ │ │ │ 7 is also Sunday on some systems)
# │ │ │ │ │ OR sun, mon, tue, wed, thu, fri, sat
# │ │ │ │ │
# * * * * *
Statefulset
StatefulSet 和 Deployment 工作负载非常类似,但它主要用于部署“有状态”的应用,它的核心能力是保存 Pod 的状态,比如最常见的如存储状态。在出现故障 Pod 需要重建时,新的 Pod 将恢复原来的状态。
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # by default is 1
minReadySeconds: 10 # by default is 0
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: registry.k8s.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
实际上,我们在工作中几乎不会以 StatefulSet 的形式部署业务系统。更多了解,请查阅官网。
DaemonSet
DaemonSet 是一种非常特殊的工作负载,你可以把它理解为节点级的守护进程,它可以为集群的每个节点都创建一个 Pod。当节点被添加时,它会在新节点启动新的 Pod,相反地,当节点被删除时,Pod 也将会被删除。
DaemonSet 经常用于下面几种业务场景。
- 存储插件:在每一个节点运行存储守护进程,例如 Ceph。
- 网络插件代理:在每一个节点上运行网络插件,以便处理节点的容器网络通信。
- 监控和日志组件:为每一个节点采集日志或者监控指标,例如 Prometheus Node Exporter 和 Fluentd。
我们在工作中也几乎不会以 DaemonSet 的方式部署业务应用。